FAQ
TensorFlow is an open-source software library developed by Google specifically for machine learning and deep learning tasks. It provides a powerful framework that allows you to build and train neural networks, which are the backbone of many machine learning algorithms.
One of the key features of TensorFlow is its ability to efficiently perform computations on large datasets. It does this by representing data as tensors, which are essentially multi-dimensional arrays. These tensors flow through a computational graph, where various mathematical operations are applied to them. This graph-based approach enables TensorFlow to distribute computations across multiple devices, such as CPUs or GPUs, for faster processing.
TensorFlow offers a high-level API called Keras, which simplifies the process of designing and training neural networks. It provides pre-built layers, activation functions, and optimization algorithms, making it easier to build complex models. Additionally, TensorFlow supports eager execution, allowing for immediate evaluation of operations without needing to define a graph.
Another significant aspect of TensorFlow is its flexibility and scalability. It supports both static and dynamic graph definitions, giving you the freedom to choose the approach that suits your needs. TensorFlow also provides tools for distributed computing, allowing you to train models on multiple machines or clusters, which is essential for handling large-scale datasets and computationally intensive tasks.
Furthermore, TensorFlow is not limited to a single programming language. It offers APIs for Python, C++, Java, and other languages, making it accessible to a wide range of developers.
Overall, TensorFlow is a powerful and versatile library that empowers researchers and developers to build and deploy machine learning models efficiently, with extensive support for various network architectures and scalable computing environments.
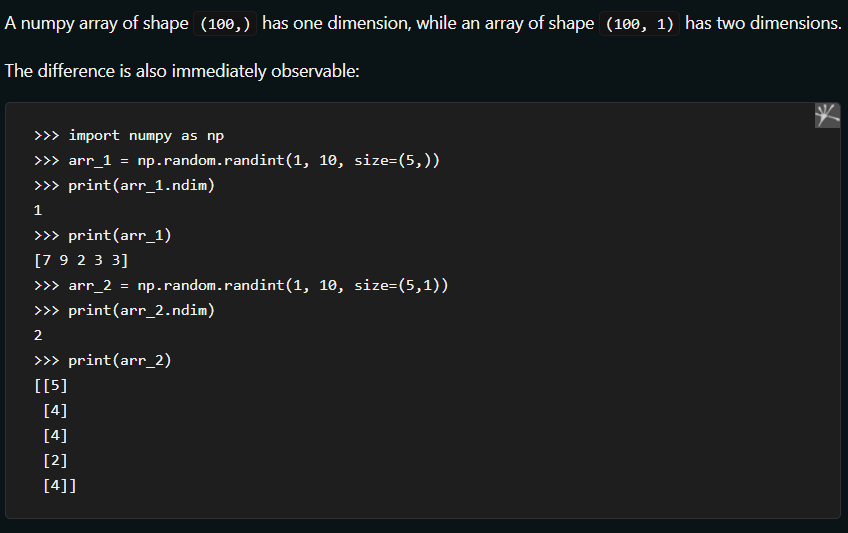
In the context of machine learning and TensorFlow, a tensor is a fundamental data structure that represents multi-dimensional arrays of numerical values. It can be thought of as a container that holds numerical data.
Tensors can have different dimensions, such as 0D (scalar), 1D (vector), 2D (matrix), or higher dimensions. For example, a 0D tensor is a single value, like a number. A 1D tensor is a sequence of values arranged in a single line, like a list of numbers. A 2D tensor is a table of values organized in rows and columns, similar to a spreadsheet.
The term "tensor" is derived from mathematics and refers to a generalization of vectors and matrices to higher dimensions. In machine learning, tensors are used to represent data, including inputs, outputs, and intermediate values in computational graphs.
Tensors in TensorFlow are designed to be efficiently processed and manipulated by various mathematical operations, such as addition, multiplication, and matrix operations. These operations can be performed on tensors of compatible shapes and sizes.
By using tensors, TensorFlow can perform computations on large datasets in parallel across multiple devices, like CPUs or GPUs, enabling faster and more efficient machine learning tasks.
In summary, a tensor is a versatile data structure used in machine learning and TensorFlow to represent multi-dimensional arrays of numerical values, allowing for efficient processing and manipulation of data during the training and evaluation of machine learning models.
Cross-validation is a technique used in machine learning to evaluate the performance of a model and estimate its generalization ability. It helps assess how well the model will perform on unseen data.
In cross-validation, the available data is divided into two parts: the training set and the validation set. The model is trained on the training set and then evaluated on the validation set. This process is repeated multiple times, with different subsets of data used for training and validation each time.
The most common form of cross-validation is called k-fold cross-validation. In k-fold cross-validation, the data is divided into k equally sized subsets or "folds." The model is trained on k-1 folds and validated on the remaining fold. This process is repeated k times, each time using a different fold as the validation set. The performance results from each fold are averaged to obtain an overall performance estimate of the model.
Cross-validation helps address the issue of overfitting, which is when a model performs well on the training data but poorly on new, unseen data. By evaluating the model on multiple subsets of data, cross-validation provides a more robust estimate of how well the model will generalize to unseen data.
It's important to note that cross-validation is typically used during the model development and tuning phase, not during the final evaluation on a completely independent test set. The final evaluation is usually performed on a separate test set that the model has never seen before.
In summary, cross-validation is a technique in machine learning that involves dividing the data into training and validation sets, repeatedly training and evaluating the model on different subsets of data. It helps assess the model's performance and generalization ability, providing a more reliable estimate of how well the model will perform on unseen data.

Bagging
- When to use it?
- When you have high variance: Your model is too sensitive to the data (e.g., it changes a lot with different training data).
- When you want to reduce overfitting: Bagging helps to make your model more stable by averaging multiple models.
- When you can train multiple models independently: Each model can be trained in parallel.
- How it works?
- Bootstrap sampling: Create multiple subsets of the training data by sampling with replacement.
- Train multiple models: Train a model on each subset.
- Aggregate predictions: Combine the predictions of all models (e.g., by averaging for regression or voting for classification).
Boosting
-
When to use it?
- When you have high bias: Your model is too simple and underfits the data.
- When you want to improve weak learners: Boosting builds a strong model by combining many weak models.
- When you can handle sequential training: Each model is trained based on the errors of the previous one, so they need to be trained in sequence.
-
How it works?
- Sequential learning: Train a model, then adjust the training data based on the errors of that model.
- Focus on difficult cases: Each subsequent model focuses more on the data points that were previously misclassified.
- Combine models: Each model’s predictions are weighted based on their accuracy, and the final prediction is a combination of all models.
Summary
- Bagging: Use when you want to reduce variance and can train models independently.
- Boosting: Use when you want to reduce bias and can train models sequentially.
Here's a simple analogy:
- Bagging: Imagine asking several friends (independently) for their opinions on a movie and then taking the average of their scores.
- Boosting: Imagine asking one friend for their opinion, then another friend to improve upon that opinion, and so on, until you get a refined score.
Overfitting is a common challenge in machine learning where a model performs exceptionally well on the training data but fails to generalize to new, unseen data. To reduce overfitting, several techniques can be applied:
- Increase Training Data: Obtaining more training data can help the model capture a broader representation of the underlying patterns in the data, reducing the chances of overfitting.
- Cross Validation : Using cross-validation techniques, such as k-fold cross-validation, helps evaluate the model's performance on multiple subsets of data, providing a more reliable estimate of its generalization ability.
- Feature Selection: Careful selection of relevant features and removing irrelevant or noisy features can help reduce overfitting. It's important to focus on the most informative features that contribute to the predictive power of the model.
- Regularization: Regularization techniques add a penalty term to the model's objective function, discouraging overly complex or extreme parameter values. Common regularization techniques include L1 regularization (Lasso) and L2 regularization (Ridge), which help constrain the model's parameters and prevent overfitting.
- Early Stopping: Monitoring the model's performance on a validation set during training and stopping the training process when the performance starts to degrade can prevent overfitting. This approach prevents the model from continuing to improve on the training data while losing its ability to generalize.
- Ensemble Learning: Ensemble methods combine multiple models to make predictions. Techniques like bagging (bootstrap aggregating) and boosting can reduce overfitting by aggregating the predictions of multiple models, thereby reducing the impact of individual models that may be prone to overfitting.
- Simplifying the Model: Reducing the complexity of the model, such as decreasing the number of layers or nodes in a neural network, or reducing the maximum depth of a decision tree, can help prevent overfitting. Simplifying the model reduces its capacity to memorize noise or irrelevant patterns in the data.
- Dropout: Dropout is a regularization technique commonly used in neural networks. It randomly drops out a fraction of the nodes or connections during training, forcing the network to learn more robust and generalizable features.
These techniques, alone or in combination, can help mitigate overfitting and improve the model's ability to generalize well to unseen data. It's important to strike a balance between model complexity and the amount of available data to achieve the best trade-off between underfitting and overfitting.